Integrations¶
OP5 - Naemon logs¶
Logstash¶
In Energy Logserver
naemon_beat.confset upELASTICSEARCH_HOST,ES_PORT,FILEBEAT_PORTCopy Energy Logserver
naemon_beat.confto/etc/logstash/conf.dBased on “FILEBEAT_PORT” if firewall is running:
sudo firewall-cmd --zone=public --permanent --add-port=FILEBEAT_PORT/tcp sudo firewall-cmd --reload
Based on amount of data that elasticsearch will receive you can also choose whether you want index creation to be based on moths or days:
index => "Energy Logserver-naemon-%{+YYYY.MM}" or index => "Energy Logserver-naemon-%{+YYYY.MM.dd}"
Copy
naemonfile to/etc/logstash/patternsand make sure it is readable by logstash processRestart logstash configuration e.g.:
sudo systemct restart logstash
Elasticsearch¶
Connect to Elasticsearch node via SSH and Install index pattern for naemon logs. Note that if you have a default pattern covering settings section you should delete/modify that in naemon_template.sh:
"settings": {
"number_of_shards": 5,
"auto_expand_replicas": "0-1"
},
./naemon_template.shEnergy Logserver Monitor¶
On Energy Logserver Monitor host install filebeat (for instance via rpm
https://www.elastic.co/downloads/beats/filebeat)In
/etc/filebeat/filebeat.ymladd:#=========================== Filebeat inputs ============================= filebeat.config.inputs: enabled: true path: configs/*.yml
You also will have to configure the output section in
filebeat.yml. You should have one logstash output:#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["LOGSTASH_IP:FILEBEAT_PORT"]
If you have few logstash instances -
Logstashsection has to be repeated on every node andhosts:should point to all of them:hosts: ["LOGSTASH_IP:FILEBEAT_PORT", "LOGSTASH_IP:FILEBEAT_PORT", "LOGSTASH_IP:FILEBEAT_PORT" ]
Create
/etc/filebeat/configscatalog.Copy
naemon_logs.ymlto a newly created catalog.Check the newly added configuration and connection to logstash. Location of executable might vary based on os:
/usr/share/filebeat/bin/filebeat --path.config /etc/filebeat/ test config /usr/share/filebeat/bin/filebeat --path.config /etc/filebeat/ test output
Restart filebeat:
sudo systemctl restart filebeat # RHEL/CentOS 7 sudo service filebeat restart # RHEL/CentOS 6
Elasticsearch¶
At this moment there should be a new index on the Elasticsearch node:
curl -XGET '127.0.0.1:9200/_cat/indices?v'
Example output:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open Energy Logserver-naemon-2018.11 gO8XRsHiTNm63nI_RVCy8w 1 0 23176 0 8.3mb 8.3mb
If the index has been created, in order to browse and visualise the data, “index pattern” needs to be added in Kibana.
OP5 - Performance data¶
Below instruction requires that between Energy Logserver node and Elasticsearch node is working Logstash instance.
Elasticsearch¶
First, settings section in Energy Logservertemplate.sh should be adjusted, either:
there is a default template present on Elasticsearch that already covers shards and replicas then settings sections should be removed from the Energy Logservertemplate.sh before executing
there is no default template - shards and replicas should be adjusted for you environment (keep in mind replicas can be added later, while changing shards count on existing index requires reindexing it)
"settings": { "number_of_shards": 5, "number_of_replicas": 0 }
In URL Energy Logserverperfdata is a name for the template - later it can be search for or modify with it.
The “template” is an index pattern. New indices matching it will have the settings and mapping applied automatically (change it if you index name for Energy Logserver perfdata is different).
Mapping name should match documents type:
"mappings": { "Energy Logserverperflogs"
Running Energy Logservertemplate.sh will create a template (not index) for Energy Logserver perf data documents.
Logstash¶
The Energy Logserverperflogs.conf contains example of input/filter/output configuration. It has to be copied to /etc/logstash/conf.d/. Make sure that the logstash has permissions to read the configuration files:
chmod 664 /etc/logstash/conf.d/Energy Logserverperflogs.conf
In the input section comment/uncomment “beats” or “tcp” depending on preference (beats if Filebeat will be used and tcp if NetCat). The port and the type has to be adjusted as well:
port => PORT_NUMBER type => "Energy Logserverperflogs"
In a filter section type has to be changed if needed to match the input section and Elasticsearch mapping.
In an output section type should match with the rest of a config. host should point to your elasticsearch node. index name should correspond with what has been set in elasticsearch template to allow mapping application. The date for index rotation in its name is recommended and depending on the amount of data expecting to be transferred should be set to daily (+YYYY.MM.dd) or monthly (+YYYY.MM) rotation:
hosts => ["127.0.0.1:9200"] index => "Energy Logserver-perflogs-%{+YYYY.MM.dd}"
Port has to be opened on a firewall:
sudo firewall-cmd --zone=public --permanent --add-port=PORT_NUMBER/tcp sudo firewall-cmd --reload
Logstash has to be reloaded:
sudo systemctl restart logstash
or
sudo kill -1 LOGSTASH_PID
Energy Logserver Monitor¶
You have to decide wether FileBeat or NetCat will be used. In case of Filebeat - skip to the second step. Otherwise:
Comment line:
54 open(my $logFileHandler, '>>', $hostPerfLogs) or die "Could not open $hostPerfLogs"; #FileBeat • Uncomment lines: 55 # open(my $logFileHandler, '>', $hostPerfLogs) or die "Could not open $hostPerfLogs"; #NetCat ... 88 # my $logstashIP = "LOGSTASH_IP"; 89 # my $logstashPORT = "LOGSTASH_PORT"; 90 # if (-e $hostPerfLogs) { 91 # my $pid1 = fork(); 92 # if ($pid1 == 0) { 93 # exec("/bin/cat $hostPerfLogs | /usr/bin/nc -w 30 $logstashIP $logstashPORT"); 94 # } 95 # }
In process-service-perfdata-log.pl and process-host-perfdata-log.pl: change logstash IP and port:
92 my $logstashIP = "LOGSTASH_IP"; 93 my $logstashPORT = "LOGSTASH_PORT";
In case of running single Energy Logserver node, there is no problem with the setup. In case of a peered environment $do_on_host variable has to be set up and the script process-service-perfdata-log.pl/process-host-perfdata-log.pl has to be propagated on all of Energy Logserver nodes:
16 $do_on_host = "EXAMPLE_HOSTNAME"; # Energy Logserver node name to run the script on 17 $hostName = hostname; # will read hostname of a node running the script
Example of command definition (/opt/monitor/etc/checkcommands.cfg) if scripts have been copied to /opt/plugins/custom/:
# command 'process-service-perfdata-log' define command{ command_name process-service-perfdata-log command_line /opt/plugins/custom/process-service-perfdata-log.pl $TIMET$ } # command 'process-host-perfdata-log' define command{ command_name process-host-perfdata-log command_line /opt/plugins/custom/process-host-perfdata-log.pl $TIMET$ }
In /opt/monitor/etc/naemon.cfg service_perfdata_file_processing_command and host_perfdata_file_processing_command has to be changed to run those custom scripts:
service_perfdata_file_processing_command=process-service-perfdata-log host_perfdata_file_processing_command=process-host-perfdata-log
In addition service_perfdata_file_template and host_perfdata_file_template can be changed to support sending more data to Elasticsearch. For instance, by adding $HOSTGROUPNAMES$ and $SERVICEGROUPNAMES$ macros logs can be separated better (it requires changes to Logstash filter config as well)
Restart naemon service:
sudo systemctl restart naemon # CentOS/RHEL 7.x sudo service naemon restart # CentOS/RHEL 7.x
If FileBeat has been chosen, append below to filebeat.conf (adjust IP and PORT):
filebeat.inputs: type: log enabled: true paths: - /opt/monitor/var/service_performance.log - /opt/monitor/var/host_performance.log tags: ["Energy Logserverperflogs"] output.logstash: # The Logstash hosts hosts: ["LOGSTASH_IP:LOGSTASH_PORT"]
Restart FileBeat service:
sudo systemctl restart filebeat # CentOS/RHEL 7.x sudo service filebeat restart # CentOS/RHEL 7.x
Kibana¶
At this moment there should be new index on the Elasticsearch node with performance data documents from Energy Logserver Monitor.
Login to an Elasticsearch node and run: curl -XGET '127.0.0.1:9200/_cat/indices?v' Example output:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open auth 5 0 7 6230 1.8mb 1.8mb
green open Energy Logserver-perflogs-2018.09.14 5 0 72109 0 24.7mb 24.7mb
After a while, if there is no new index make sure that:
- Naemon is runnig on Energy Logserver node
- Logstash service is running and there are no errors in: /var/log/logstash/logstash-plain.log
- Elasticsearch service is running an there are no errors in: /var/log/elasticsearch/elasticsearch.log
If the index has been created, in order to browse and visualize the data “index pattern” needs to be added to Kibana.
- After logging in to Kibana GUI go to Settings tab and add Energy Logserver-perflogs-* pattern. Chose @timestamp time field and click Create.
- Performance data logs should be now accessible from Kibana GUI Discovery tab ready to be visualize.
OP5 Beat¶
The op5beat is small agent for collecting metrics from op5 Monitor.
The op5beat is located in the installation directory: utils/op5integration/op5beat
Installation for Centos7 and newer¶
Copy the necessary files to the appropriate directories:
cp -rf etc/* /etc/ cp -rf usr/* /usr/ cp -rf var/* /var/
Configure and start op5beat service (systemd):
cp -rf op5beat.service /usr/lib/systemd/system/ systemctl daemon-reload systemctl enable op5beat systemctl start op5beat
Installation for Centos6 and older¶
Copy the necessary files to the appropriate directories:
cp -rf etc/* /etc/ cp -rf usr/* /usr/ cp -rf var/* /var/
Configure and start op5beat service:
sysV init:
cp -rf op5beat.service /etc/rc.d/init.d/op5beat chkconfig op5beat on service op5beat start
supervisord (optional):
yum install supervisor cp -rf supervisord.conf /etc/supervisord.conf
The Grafana instalation¶
To install the Grafana application you should:
add necessary repository to operating system:
[root@localhost ~]# cat /etc/yum.repos.d/grafan.repo [grafana] name=grafana baseurl=https://packagecloud.io/grafana/stable/el/7/$basearch repo_gpgcheck=1 enabled=1 gpgcheck=1 gpgkey=https://packagecloud.io/gpg.key https://grafanarel.s3.amazonaws.com/RPM-GPG-KEY-grafana sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt [root@localhost ~]#
install the Grafana with following commands:
[root@localhost ~]# yum search grafana Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: ftp.man.szczecin.pl * extras: centos.slaskdatacenter.com * updates: centos.slaskdatacenter.com =========================================================================================================== N/S matched: grafana =========================================================================================================== grafana.x86_64 : Grafana pcp-webapp-grafana.noarch : Grafana web application for Performance Co-Pilot (PCP) Name and summary matches only, use "search all" for everything. [root@localhost ~]# yum install grafana
to run application use following commands:
[root@localhost ~]# systemctl enable grafana-server Created symlink from /etc/systemd/system/multi-user.target.wants/grafana-server.service to /usr/lib/systemd/system/grafana-server.service. [root@localhost ~]# [root@localhost ~]# systemctl start grafana-server [root@localhost ~]# systemctl status grafana-server ● grafana-server.service - Grafana instance Loaded: loaded (/usr/lib/systemd/system/grafana-server.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2018-10-18 10:41:48 CEST; 5s ago Docs: http://docs.grafana.org Main PID: 1757 (grafana-server) CGroup: /system.slice/grafana-server.service └─1757 /usr/sbin/grafana-server --config=/etc/grafana/grafana.ini --pidfile=/var/run/grafana/grafana-server.pid cfg:default.paths.logs=/var/log/grafana cfg:default.paths.data=/var/lib/grafana cfg:default.paths.plugins=/var... [root@localhost ~]#
To connect the Grafana application you should:
define the default login/password (line 151;154 in config file):
[root@localhost ~]# cat /etc/grafana/grafana.ini 148 #################################### Security #################################### 149 [security] 150 # default admin user, created on startup 151 admin_user = admin 152 153 # default admin password, can be changed before first start of grafana, or in profile settings 154 admin_password = admin 155
restart grafana-server service:
systemctl restart grafana-server
Login to Grafana user interface using web browser: http://ip:3000

use login and password that you set in the config file.
Use below example to set conection to Elasticsearch server:
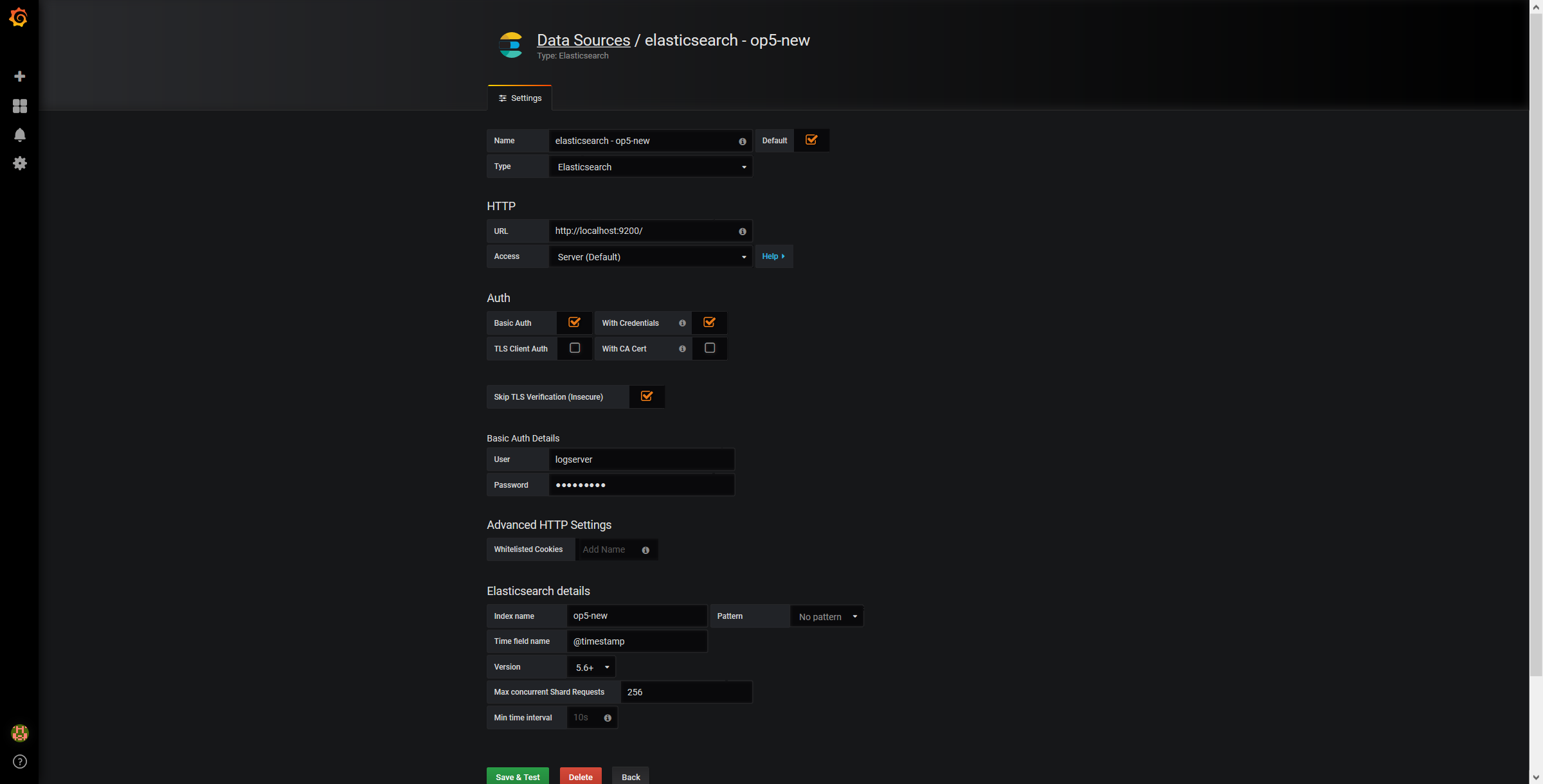
The Beats configuration¶
Kibana API¶
Reference link: https://www.elastic.co/guide/en/kibana/master/api.html
After installing any of beats package you can use ready to use dashboard related to this beat package. For instance dashboard and index pattern are available in /usr/share/filebeat/kibana/6/ directory on Linux.
Before uploading index-pattern or dashboard you have to authorize yourself:
Set up login/password/kibana_ip variables, e.g.:
login=my_user password=my_password kibana_ip=10.4.11.243
Execute command which will save authorization cookie:
curl -c authorization.txt -XPOST -k "https://${kibana_ip}:5601/login" -d "username=${username}&password=${password}&version=6.2.3&location=https%3A%2F%2F${kibana_ip}%3A5601%2Flogin"
Upload index-pattern and dashboard to Kibana, e.g.:
curl -b authorization.txt -XPOST -k "https://${kibana_ip}:5601/api/kibana/dashboards/import" -H 'kbn-xsrf: true' -H 'Content-Type: application/json' -d@/usr/share/filebeat/kibana/6/index-pattern/filebeat.json curl -b authorization.txt -XPOST -k "https://${kibana_ip}:5601/api/kibana/dashboards/import" -H 'kbn-xsrf: true' -H 'Content-Type: application/json' -d@/usr/share/filebeat/kibana/6/dashboard/Filebeat-mysql.json
When you want to upload beats index template to Ealsticsearch you have to recover it first (usually you do not send logs directly to Es rather than to Logstash first):
/usr/bin/filebeat export template --es.version 6.2.3 >> /path/to/beats_template.json
After that you can upload it as any other template (Access Es node with SSH):
curl -XPUT "localhost:9200/_template/Energy Logserverperfdata" -H'Content-Type: application/json' -d@beats_template.json
Wazuh integration¶
Energy Logserver can integrate with the Wazuh, which is lightweight agent is designed to perform a number of tasks with the objective of detecting threats and, when necessary, trigger automatic responses. The agent core capabilities are:
- Log and events data collection
- File and registry keys integrity monitoring
- Inventory of running processes and installed applications
- Monitoring of open ports and network configuration
- Detection of rootkits or malware artifacts
- Configuration assessment and policy monitoring
- Execution of active responses
The Wazuh agents run on many different platforms, including Windows, Linux, Mac OS X, AIX, Solaris and HP-UX. They can be configured and managed from the Wazuh server.
Deploying Wazuh Server¶
https://documentation.wazuh.com/3.13/installation-guide/installing-wazuh-manager/linux/centos/index.html
Deploing Wazuh Agent¶
https://documentation.wazuh.com/3.13/installation-guide/installing-wazuh-agent/index.html
Filebeat configuration¶
2FA authorization with Google Auth Provider (example)¶
Software used (tested versions):¶
- NGiNX (1.16.1 - from CentOS base reposiory)
- oauth2_proxy (https://github.com/pusher/oauth2_proxy/releases - 4.0.0)
The NGiNX configuration:¶
Copy the ng_oauth2_proxy.conf to
/etc/nginx/conf.d/;server { listen 443 default ssl; server_name logserver.local; ssl_certificate /etc/kibana/ssl/logserver.org.crt; ssl_certificate_key /etc/kibana/ssl/logserver.org.key; ssl_session_cache builtin:1000 shared:SSL:10m; add_header Strict-Transport-Security max-age=2592000; location /oauth2/ { proxy_pass http://127.0.0.1:4180; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Scheme $scheme; proxy_set_header X-Auth-Request-Redirect $request_uri; # or, if you are handling multiple domains: # proxy_set_header X-Auth-Request-Redirect $scheme://$host$request_uri; } location = /oauth2/auth { proxy_pass http://127.0.0.1:4180; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Scheme $scheme; # nginx auth_request includes headers but not body proxy_set_header Content-Length ""; proxy_pass_request_body off; } location / { auth_request /oauth2/auth; error_page 401 = /oauth2/sign_in; # pass information via X-User and X-Email headers to backend, # requires running with --set-xauthrequest flag auth_request_set $user $upstream_http_x_auth_request_user; auth_request_set $email $upstream_http_x_auth_request_email; proxy_set_header X-User $user; proxy_set_header X-Email $email; # if you enabled --pass-access-token, this will pass the token to the backend auth_request_set $token $upstream_http_x_auth_request_access_token; proxy_set_header X-Access-Token $token; # if you enabled --cookie-refresh, this is needed for it to work with auth_request auth_request_set $auth_cookie $upstream_http_set_cookie; add_header Set-Cookie $auth_cookie; # When using the --set-authorization-header flag, some provider's cookies can exceed the 4kb # limit and so the OAuth2 Proxy splits these into multiple parts. # Nginx normally only copies the first `Set-Cookie` header from the auth_request to the response, # so if your cookies are larger than 4kb, you will need to extract additional cookies manually. auth_request_set $auth_cookie_name_upstream_1 $upstream_cookie_auth_cookie_name_1; # Extract the Cookie attributes from the first Set-Cookie header and append them # to the second part ($upstream_cookie_* variables only contain the raw cookie content) if ($auth_cookie ~* "(; .*)") { set $auth_cookie_name_0 $auth_cookie; set $auth_cookie_name_1 "auth_cookie__oauth2_proxy_1=$auth_cookie_name_upstream_1$1"; } # Send both Set-Cookie headers now if there was a second part if ($auth_cookie_name_upstream_1) { add_header Set-Cookie $auth_cookie_name_0; add_header Set-Cookie $auth_cookie_name_1; } proxy_pass https://127.0.0.1:5601; # or "root /path/to/site;" or "fastcgi_pass ..." etc } }
Set
ssl_certificateandssl_certificate_keypath in ng_oauth2_proxy.conf
When SSL is set using nginx proxy, Kibana can be started with http.
However, if it is to be run with encryption, you also need to change proxy_pass to the appropriate one.
The oauth2_proxy configuration:¶
Create a directory in which the program will be located and its configuration:
mkdir -p /usr/share/oauth2_proxy/ mkdir -p /etc/oauth2_proxy/
Copy files to directories:
cp oauth2_proxy /usr/share/oauth2_proxy/ cp oauth2_proxy.cfg /etc/oauth2_proxy/
Set directives according to OAuth configuration in Google Cloud project
cfg client_id = client_secret = # the following limits domains for authorization (* - all) email_domains = [ "*" ]
Set the following according to the public hostname:
cookie_domain = "kibana-host.org"
In case og-in restrictions for a specific group defined on the Google side:
Create administrative account: https://developers.google.com/identity/protocols/OAuth2ServiceAccount ;
Get configuration to JSON file and copy Client ID;
On the dashboard of the Google Cloud select “APIs & Auth” -> “APIs”;
Click on “Admin SDK” and “Enable API”;
Follow the instruction at https://developers.google.com/admin-sdk/directory/v1/guides/delegation#delegate_domain-wide_authority_to_your_service_account and give the service account the following permissions:
https://www.googleapis.com/auth/admin.directory.group.readonly https://www.googleapis.com/auth/admin.directory.user.readonly
Follow the instructions to grant access to the Admin API https://support.google.com/a/answer/60757
Create or select an existing administrative email in the Gmail domain to flag it
google-admin-emailCreate or select an existing group to flag it
google-groupCopy the previously downloaded JSON file to
/etc/oauth2_proxy/.In file oauth2_proxy set the appropriate path:
google_service_account_json =
Service start up¶
- Start the NGiNX service
- Start the oauth2_proxy service
/usr/share/oauth2_proxy/oauth2_proxy -config="/etc/oauth2_proxy/oauth2_proxy.cfg"
In the browser enter the address pointing to the server with the Energy Logserver installation
–type=alias
#### Import aliases into ES
```bash
elasticdump \
--input=./alias.json \
--output=http://es.com:9200 \
--type=alias
Backup templates to a file¶
elasticdump \
--input=http://es.com:9200/template-filter \
--output=templates.json \
--type=template
Import templates into ES¶
elasticdump \
--input=./templates.json \
--output=http://es.com:9200 \
--type=template
Split files into multiple parts¶
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--fileSize=10mb
Import data from S3 into ES (using s3urls)¶
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input "s3://${bucket_name}/${file_name}.json" \
--output=http://production.es.com:9200/my_index
Export ES data to S3 (using s3urls)¶
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input=http://production.es.com:9200/my_index \
--output "s3://${bucket_name}/${file_name}.json"
Import data from MINIO (s3 compatible) into ES (using s3urls)¶
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input "s3://${bucket_name}/${file_name}.json" \
--output=http://production.es.com:9200/my_index
--s3ForcePathStyle true
--s3Endpoint https://production.minio.co
Export ES data to MINIO (s3 compatible) (using s3urls)¶
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input=http://production.es.com:9200/my_index \
--output "s3://${bucket_name}/${file_name}.json"
--s3ForcePathStyle true
--s3Endpoint https://production.minio.co
Import data from CSV file into ES (using csvurls)¶
elasticdump \
# csv:// prefix must be included to allow parsing of csv files
# --input "csv://${file_path}.csv" \
--input "csv:///data/cars.csv"
--output=http://production.es.com:9200/my_index \
--csvSkipRows 1 # used to skip parsed rows (this does not include the headers row)
--csvDelimiter ";" # default csvDelimiter is ','
Copy a single index from a elasticsearch:¶
elasticdump \
--input=http://es.com:9200/api/search \
--input-index=my_index \
--output=http://es.com:9200/api/search \
--output-index=my_index \
--type=mapping
2FA with Nginx and PKI certificate¶
Seting up Nginx Client-Certificate for Kibana¶
1. Installing NGINX¶
The following link directs you to the official NGINX documentation with installation instructions.
2. Creating client-certificate signing CA¶
Now, we’ll create our client-certificate signing CA. Let’s create a directoru at thr root file system to pertform this work.
cd /etc/nginx
mkdir CertificateAuthCA
cd CertificateAuthCA
chown root:www-data /etc/nginx/CertificateAuthCA/
chmod 770 /etc/nginx/CertificateAuthCA/
This set of permissions will grant the user root (replace with the username of your own privileged user used to setup the box) and the www-data group (the context in which nginx runs by default). It will grant everyone else no permission to the sensitive file that is your root signing key.
You will be prompted to set a passphrase. Make sure to set it to something yuo’ll remember.
openssl genrsa -des3 -out myca.key 4096
Makes the signing CA valid for 10 years. Change as requirements dictate. You will be asked to fill in attributes fo your CA.
openssl req -new -x509 -days 3650 -key myca.key -out myca.crt
3. Creating a client keypair¶
This will be performed once for EACH user. It can easily be scripted as part of a user provisioning process.
You will be prompted for passphrase which will be distributed to your user with the certificate.
NOTE DO NOT ever distributed the passphrase set above for your root CA’s private key. Make sure you understand this distinction!
openssl genrsa -des3 -out testuser.key 2048
openssl req -new -key testuser.key -out testuser.csr
Sign with our certificate-signing CA. This Certificate will be valid for one year. Change as per your requirements. You can increment the serial if you have t oreissue the CERT.
openssl x509 -req -days 365 -in testuser.csr -CA myca.crt -CAkey myca.key -set_serial 01 -out testuser.crt
For Windows clients, the key material can be combined into a single PFX. You will be prompted fo the passpharase you set above.
openssl pkcs12 -export -out testuser.pfx -inkey testuser.key -in testuser.crt -certfile myca.crt
This includes the public portion of your CA’s key to allows Windows to trust you internally signed CA.
4. Creating the nginx configuration file¶
Here, we’ll create the nginx configuration file to serve a site for our authenticated reverse proxy.
Creating site certificates (The ones that will be publicly signed by a CA such as from SSLTrust).
chown -R root:www-data /etc/nginx/CertificateAuthCA
chmod 700 /etc/nginx/CertificateAuthCA
Generate an RSA Private Key (You will be prompted to a passphrase and fill out attributes).
openssl genrsa -out ./domain.com.key 2048
Use it to create a CSR to send us.
openssl req -new -sha256 -key ./domain.com.key -out ./domain.com.csr
Creating CERT for domain.com
openssl x509 -req -days 365 -in domain.com.csr -CA myca.crt -CAkey myca.key -set_serial 01 -out domain.com.crt
Remove the passphrase from your key (you will be prompted for passphrase generated abov).
openssl rsa -in domain.com.key -out domain.com.key.nopass
Create nginx sites-available directory.
cd /etc/nginx
mkdir sites-available
cd sites-available
And create a new configuration file(we use vim, you could use nano or other fav text editor).
touch proxy.conf
vim proxy.conf
5. Setting configurations in configuration file paste¶
Before you set configurations make sure that you have installed and enabled firewalld.
In configuration file(proxy.conf):
server {
listen 443; ## REMEMBER ! Listen port and firewall port must match !!
ssl on;
server_name 192.168.3.87; ## Set up your IP as server_name
proxy_ssl_server_name on;
ssl_certificate /etc/nginx/CertificateAuthCA/domain.com.crt; ## Use your domain key
ssl_certificate_key /etc/nginx/CertificateAuthCA/domain.com.key.nopass; ## Use your own trusted certificate without password
ssl_client_certificate /etc/nginx/CertificateAuthCA/myca.key; ## Use your own trusted certificate from CA/SSLTrust
ssl_verify_client on;
## You can optionally capture the error code and redirect it to a custom page
## error_page 495 496 497 https://someerrorpage.yourdomain.com;
ssl_prefer_server_ciphers on;
ssl_protocols TLSv1.1 TLSv1.2;
ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:ECDHE-RSA-RC4-SHA:ECDHE-ECDSA-RC4-SHA:RC4-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!3DES:!MD5:!PSK';
keepalive_timeout 10;
ssl_session_timeout 5m;
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://localhost:5601/; ##proxy_pass for Kibana
}
}
6. Create a symlink to enable your site in nginx¶
In the nginx directory is nginx.conf file in which we will load modular configuration files (include). Based on /etc/nginx/conf.d/*.conf; create symlink using proxy.conf.
cd /etc/nginx
ln -s /etc/nginx/sites-available/proxy.conf /etc/nginx/conf.d/proxy.conf
7. Restart nginx¶
systemctl restart nginx
8. Importing the Client Certificate on to a Windows Machine¶
Double click the .PFX file, select “Current User”. 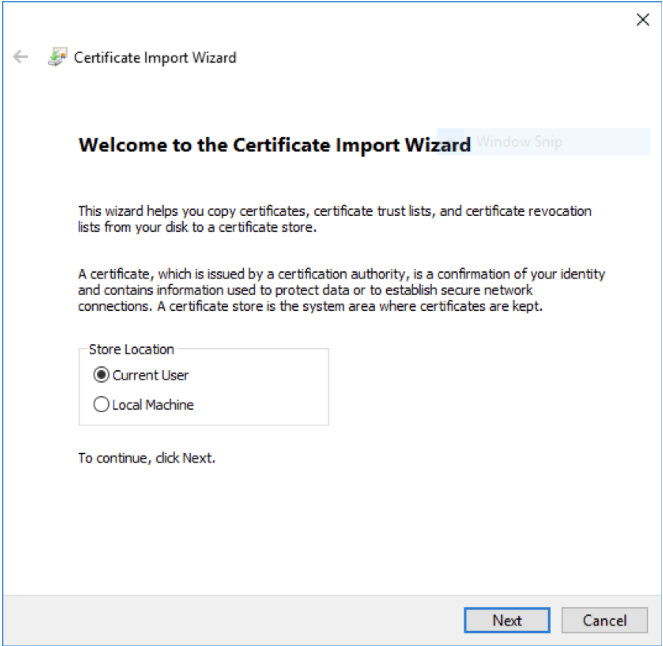
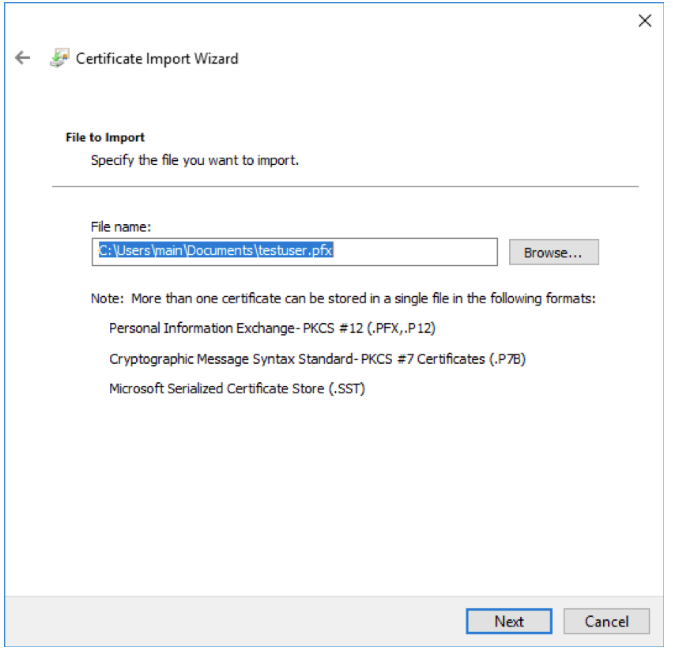
If you set a passphrase on the PFX above, enter it here. Otherwise leave blank and hit next. 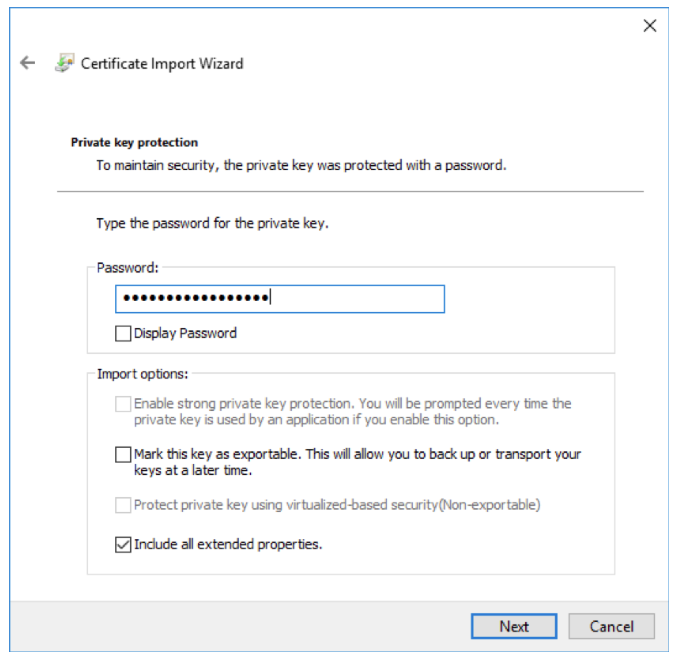
Next, add the site in question to “trusted sites” in Internet Explorer. This will allow the client certificate to be sent to the site for verification(Trusting it in Internet Explorer will trust it in chrome as well).
When you next visite the site, you should be prompted to select a client certificate. Select “OK” and you’re in 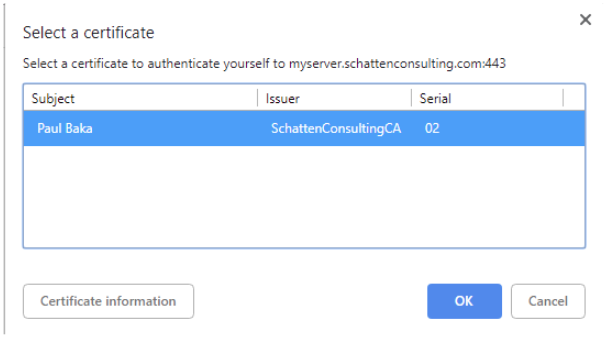
Embedding dashboard in iframe¶
It is possible to send alerts containing HTML iframe as notification content. For example:
<a href="https://siem-vip:5601/app/kibana#/discover/72503360-1b25-11ea-bbe4-d7be84731d2c?_g=%28refreshInterval%3A%28display%3AOff%2Csection%3A0%2Cvalue%3A0%29%2Ctime%3A%28from%3A%272021-03-03T08%3A36%3A50Z%27%2Cmode%3Aabsolute%2Cto%3A%272021-03-04T08%3A36%3A50Z%27%29%29" target="_blank" rel="noreferrer">https://siem-vip:5601/app/kibana#/discover/72503360-1b25-11ea-bbe4-d7be84731d2c?_g=%28refreshInterval%3A%28display%3AOff%2Csection%3A0%2Cvalue%3A0%29%2Ctime%3A%28from%3A%272021-03-03T08%3A36%3A50Z%27%2Cmode%3Aabsolute%2Cto%3A%272021-03-04T08%3A36%3A50Z%27%29%29</a>
If you want an existing HTTP session to be used to display the iframe content, you need to set the following parameters in the /etc/kibana/kibana.yml file:
login.isSameSite: "Lax"
login.isSecure: true
Possible values for isSameSite are: “None”, “Lax”, “Strict”, false
For isSecure: false or true
Integration with AWS service¶
The scope of integration¶
The integration of Energy Logserver with the AWS cloud environment was prepared based on the following requirements:
- General information of the EC2 area, i.e .:
- number of machines
- number of CPUs
- amount of RAM
- General information of the RDS area, i.e.:
- Number of RDS instances
- The number of RDS CPUs
- Amount of RDS RAM
- EC2 area information containing information for each machine i.e .:
- list of tags;
- cloudwatch alarms configured;
- basic information (e.g. imageID, reservtionid, accountid, launch date, private and public address, last backup, etc.);
- list of available metrics in cloudwatch;
- list of snapshots;
- AMI list;
- cloudtrail (all records, with detailed details).
- Information on Backups of EC2 and RDS instances
- Search for S3 objects, shoes, AMI images
- Downloading additional information about other resources, ie IG, NAT Gateway, Transit Gateway.
- Monitoring changes in the infrastructure based on Cloudtrail logs;
- Monitoring costs based on billing and usage reports.
- Monitoring the Security Group and resources connected to them and resources not connected to the Security Group
- Monitoring user activity and inactivity.
- Integration supports service for multiple member accounts in AWS organization
The integration uses a Data Collector, i.e. the Energy Logserver host, which is responsible for receiving data from external sources.
Data download mechanism¶
The integration was prepared based on AWS (CLI), a unified tool for managing AWS services, with which it is possible to download and monitor many AWS services from the command line. The AWS (CLI) tool is controlled by the Energy Logserver data collector, which execute commands at specified intervals and captures the results of data received from the AWS service. The obtained data is processed and enriched and, as a result, saved to the Energy Logserver indexes.
AWS Cost & Usage Report¶
The integration of Energy Logserver with the AWS billing environment requires access to AWS Cost & Usage reports, which generated in accordance with the agreed schedule constitute the basic source of data for cost analysis in Energy Logserver. The generated report is stored on S3 in the bucket defined for this purpose and cyclically downloaded from it by the Energy Logserver collector. After the report is downloaded, it is processed and saved to a dedicated Elasticsearch index. The configuration of generating and saving a report to S3 is described in the AWS documentation: https://aws.amazon.com/aws-cost-management/aws-cost-and-usage-reporting/.
Cloud Trail¶
The integration of the Energy Logserver with the AWS environment in order to receive events from the AWS environment requires access to the S3 bucket, on which the so-called AWS Trails. The operation of the Energy Logserver collector is based on periodical checking of the “cloudtraillogs” bucket and downloading new events from it. After the events are retrieved, they are processed so that the date the event occurred matches the date the document was indexed. The AWS Trail creation configuration is described in the AWS documentation: https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-create-a-trail-using-the-console-first-time.html#creating-a-trail-in-the-console.
Configuration¶
Configuration of access to the AWS account¶
Configuration of access to AWS is in the configuration file of the AWS service (CLI), which was placed in the home directory of the Logstash user:
/home/logstash/.aws/config
[default]
aws_access_key_id=A************************4
aws_secret_access_key=*******************************************u
The “default” section contains aws_access_key_id and aws_secret_access_key. Configuration file containing the list of AWS accounts that are included in the integration:
/etc/logstash/lists/account.txt
Configuration of AWS profiles¶
AWS profiles allow you to navigate to different AWS accounts using the defined AWS role for example : “LogserverReadOnly”. Profiles are defined in the configuration file:
/home/logstash/.aws/config
Profile configuration example:
[profile 111111111222]
role_arn = arn: aws: iam :: 111111111222: role / LogserverReadOnly
source_profile = default
region = eu-west-1
output = json
The above section includes
- profile name;
- role_arn - definition of the account and the role assigned to the account;
- source_profile - definition of the source profile;
- region - AWS region;
- output - the default format of the output data.
Configure S3 buckets scanning¶
The configuration of scanning buckets and S3 objects for the “s3” dashboard was placed in the following configuration files:
- /etc/logstash/lists/bucket_s3.txt - configuration of buckets that are included in the scan;
- /etc/logstash/lists/account_s3.txt - configuration of accounts that are included in the scan;
Configuration of AWS Cost & Usage reports¶
Downloading AWS Cost & Usage reports is done using the script: “/etc/logstash/lists/bin/aws_get_billing.sh”
In which the following parameters should be set:
- BUCKET = bucket_bame - bucket containing packed rarpotes;
- PROFILE = profile_name - a profile authorized to download reports from the bucket.
Logstash Pipelines¶
Integration mechanisms are managed by the Logstash process, which is responsible for executing scripts, querying AWS, receiving data, reading data from files, processing the received data and enriching it and, as a result, submitting it to the Energy Logserver index. These processes were set up under the following Logstash pipelines:
- pipeline.id: aws
path.config: "/etc/logstash/aws/conf.d/*.conf"
pipeline.workers: 1
- pipeline.id: awstrails
path.config: "/etc/logstash/awstrails/conf.d/*.conf"
pipeline.workers: 1
- pipeline.id: awss3
path.config: "/etc/logstash/awss3/conf.d/*.conf"
pipeline.workers: 1
- pipeline.id: awsbilling
path.config: "/etc/logstash/awsbilling/conf.d/*.conf"
pipeline.workers: 1
Configuration of AWS permissions and access¶
To enable the correct implementation of the integration assumptions in the configuration of the IAM area, an Logserver-ReadOnly account was created with programming access with the following policies assigned:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"backup:Describe*",
"backup:Get*",
"backup:List*",
"cloudwatch:Describe*",
"cloudwatch:Get*",
"cloudwatch:List*",
"ec2:Describe*",
"iam:GenerateCredentialReport",
"iam:GetCredentialReport",
"logs:Describe*",
"logs:Get*",
"rds:Describe*",
"rds:List*",
"tag:Get*"
],
"Resource": "*"
},
{
"Sid": "AllowSpecificS3ForLogServer",
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::veoliaplcloudtraillogs",
"arn:aws:s3:::veoliaplcloudtraillogs/*"
]
}
]
}
Data indexing¶
The data in the indexes has been divided into the following types:
- awscli-* - storing volumetric data about AWS infrastructure;
- awsbilling-* - storing billing data from billing reports;
- awscli-trail-* - storing AWS environment events / logs from CloudTrail;
- awsusers-000001 - storing data about users and administrators of the AWS service.
Dashboards¶
The data collected in the integration process has been visualized and divided into the following sections (dashboards):
- Overview - The section provides an overview of the quantitative state of the environment
- EC2 - the section contains details about the EC2 instance;
- RDS - the section contains details about RDS instances;
- AMI - the section contains details about Images;
- S3 - section for searching for objects and buckets S3;
- Snapshots - section for reviewing snapshots taken;
- Backups - section to review the backups made;
- CloudTrail - a section for analyzing logs downloaded from CloudTrail;
- IAM - a section containing user and administrator activity and configuration of AWS environment access accounts;
- Billing - AWS service billing section;
- Gateways - section containing details and configuration of AWS Gateways.
Overview¶
The following views are included in the “Overview” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Overview Selector - active selector used to filter sections;
- [AWS] Total Instances - metric indicator of the number of EC2 instances;
- [AWS] Total CPU Running Instances - metric indicator of the number of CPUs running EC2 instances;
- [AWS] Total Memory Running Instances - metric indicator of RAM [MB] amount of running EC2 instances;
- [AWS] Total RDS Instances - metric indicator of the number of RDS instances;
- [AWS] Total CPU Running RDS - metric indicator of the number of CPUs running RDS instances;
- [AWS] Total Memory Running RDS - metric indicator of the amount of RAM [GB] of running RDS instances;
- [AWS] Instance List - an array containing aggregated details about an EC2 instance;
- [AWS] RDS Instance List - an array containing aggregated details about an EC2 instance;
- [AWS] Alarm List - table containing the list of AWS environment alarms;
- [AWS] Tags List - an array containing a list of AWS tags;
- [AWS] CloudWatch Metrics - table containing a list of AWS metrics;
EC2¶
The following views have been placed in the “EC2” section:
- [AWS] Navigation - navigation between sections;
- [AWS] State Selector - active selector used to filter sections;
- [AWS] Total Instances - metric indicator of the number of EC2 instances;
- [AWS] Total CPU Running Instances - metric indicator of the number of CPUs running EC2 instances;
- [AWS] Running histogram - graphical interpretation of the instance status in the timeline;
- [AWS] Total Memory Running Instances - metric indicator of RAM [MB] amount of running EC2 instances;
- [AWS] OP5 Monitored Count - metric indicator of monitored instances in the OP5 Monitor system;
- [AWS] OP5 NOT Monitored Count - metric indicator of unmonitored instances in the OP5 Monitor system;
- [AWS] OP5 Monitored Details - a table containing a list of instances with monitoring details in the OP5 Monitoring system;
- [AWS] Instance Details List - table containing details of the EC2 instance;
- [AWS] CloudWatch Metrics - table containing details of EC2 metrics downloaded from AWS service;
RDS¶
The following views have been placed in the “RDS” section:
- [AWS] Navigation - navigation between sections;
- [AWS] RDS State Selector - active selector used for section filtering;
- [AWS] Total RDS Instances - metric indicator of the number of RDS instances;
- [AWS] Total CPU Running RDS - metric indicator of the number of CPUs running RDS instances;
- [AWS] RDS Running histogram - graphical interpretation of the instance status in the timeline;
- [AWS] RDS Instance Details - a table containing aggregated details of a RDS instance;
- [AWS] RDS Details - table containing full details of the RDS instance;
- [AWS] CloudWatch Metrics - table containing details of EC2 metrics downloaded from AWS service;
AMI¶
The following views have been placed in the “AMI” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Image Selector - active selector used to filter sections;
- [AWS] Image Details - a table containing full details of the images taken;
- [AWS] Image by Admin Details - a table containing full details of images made by the administrator;
- [AWS] AMI type by time - graphical interpretation of image creation presented in time;
Security¶
The following views have been placed in the “Security” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Security Selector - active selector used to filter sections;
- [AWS] Security Group ID by InstanceID - a table containing Security Groups with assigned Instances;
- [AWS] Instance by Security Group - a table containing Instances with assigned Security Groups and details;
- [AWS] Security Group connect state - table containing the status of connecting the Security Groups to the EC2 and RDS instances.
Snapshots¶
The following views have been placed in the “Snapshots” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Snapshot Selector - active selector used to filter sections;
- [AWS] Snapshots List - a view containing a list of snapshots made with details;
- [AWS] Snapshots by time - graphical interpretation of creating snapshots over time;
Backups¶
The following views have been placed in the “Backup” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Backup Selector - active selector used to filter sections;
- [AWS] Backup List - view containing the list of completed Backup with details;
- [AWS] Backup by time - graphical interpretation of backups presented in time;
CloudTrail¶
The following views have been placed in the “CloudTrail” section:
- [AWS] Navigation - navigation between sections;
- [AWS] Event Selector - active selector used to filter sections;
- [AWS] Events Name Activity - event activity table with event details;
- [AWS] CloudTrail - graphical interpretation of generating events in the AWS service presented over time;
IAM¶
The following views have been placed in the “IAM” section:
- [AWS] Navigation - navigation between sections;
- [AWS] IAM Selector - active selector used to filter sections;
- [AWS] IAM Details - the table contains AWS service users, configured login methods, account creation time and account assignment;
- [AWS] User last login - user activity table containing the period from the last login depending on the login method;
Gateways¶
The following views have been placed in the Gateways section:
- [AWS] Navigation - navigation between sections;
- [AWS] Gateways Selector - active selector used to filter sections;
- [AWS] Internet Gateway - details table of configured AWS Internet Gateways;
- [AWS] Transit Gateways - details table of configured AWS Transit Gateways;
- [AWS] Nat Gateway - details table of configured AWS Nat Gateways;
Integration with Azure / o365¶
Introduction¶
The goal of the integration is to create a single repository with aggregated information from multiple Azure / o365 accounts or subscriptions and presented in a readable way with the ability to search, analyze and generate reports.
Scope of Integration¶
The scope of integration include:
- User activity:
- Event category,
- Login status,
- Client application,
- Location,
- Type of activity,
- Login problems and their reasons.
- Infrastructure Metrics:
- Azure Monitor Metrics (or Metrics) is a platform service that provides a single source for monitoring Azure resources.
- Application Insights is an extensible Application Performance Management (APM) service for web developers on multiple platforms and can be used for live web application monitoring - it automatically detects performance anomalies.
System components¶
Logstash¶
Logstash is an event collector and executor of queries which, upon receipt, are initially processed and sent to the event buffer.
Kafka¶
Component that enables buffering of events before they are saved on Energy Logserver Data servers. Kafka also has the task of storing data when the Energy Logserver Data nodes are unavailable.
Energy Logserver Data¶
The Energy Logserver cluster is responsible for storing and sharing data.
Energy Logserver GUI¶
Energy Logserver GUI is a graphical tool for searching, analyzing and visualizing data. It has an alert module that can monitor the collected metrics and take action in the event of a breach of the permitted thresholds.
Data sources¶
Energy Logserver can access metrics from the Azure services via API. Service access can be configured with the same credentials if the account was configured with Azure AD. Configuration procedures:
- https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal
- https://dev.loganalytics.io/documentation/Authorization/AAD-Setup
- https://dev.applicationinsights.io/quickstart/
Azure Monitor datasource configuration¶
To enable an Azure Monitor data source, the following information from the Azure portal is required:
- Tenant Id (Azure Active Directory -> Properties -> Directory ID)
- Client Id (Azure Active Directory -> App Registrations -> Choose your app -> Application ID)
- Client Secret (Azure Active Directory -> App Registrations -> Choose your app -> Keys)
- Default Subscription Id (Subscriptions -> Choose subscription -> Overview -> Subscription ID)
Azure Insights datasource configuration¶
To enable an Azure Insights data source, the following information is required from the Azure portal:
- Application ID
- API Key
Azure Command-Line Interface¶
To verify the configuration and connect Energy Logserver to the Azure cloud, it is recommended to use the Azure command line interface:
- https://docs.microsoft.com/en-us/cli/azure/?view=azure-cli-latest
This tool deliver a set of commands for creating and managing Azure resources. Azure CLI is available in Azure services and is designed to allow you to work quickly with Azure with an emphasis on automation. Example command:
- Login to the Azure platform using azure-cli:
az login --service-principal -u $ (client_id) -p $ (client_secret) --tenant $ (tenant_id)
Permission¶
The following permissions are required to access the metrics:
- Logon,
- Geting a resource list with an ID (az resource list),
- Geting a list of metrics for a given resource (az monitor metrics list-definitions),
- Listing of metric values for a given resource and metric (az monitor metrics list).
Service selection¶
The service is selected by launching the appropriate pipeline in Logstash collectors:
- Azure Meters
- Azure Application Insights The collector’s queries will then be properly adapted to the chosen service.
Azure Monitor metrics¶
Sample metrics:
- Microsoft.Compute / virtualMachines - Percentage CPU
- Microsoft.Network/networkInterfaces - Bytes sent
- Microsoft.Storage/storageAccounts - Used Capacity
The Logstash collector gets the metrics through the following commands:
- downloading a list of resources for a given account: /usr/bin/az resource list
- downloading a list of resource-specific metrics: /usr/bin/az monitor metrics list-definitions –resource $ (resource_id)
- for a given resource, downloading the metric value in the 1-minute interval /usr/bin/az monitor metrics list –resource “$ (resource_id)” –metric “$ (metric_name)”
Azure Monitor metric list:
- https://docs.microsoft.com/en-us/azure/azure-monitor/essentials/metrics-supported
The downloaded data is decoded by the filter logstash:
filter {
ruby {
code => "
e = event.to_hash
data = e['value'][0]['timeseries'][0]['data']
for d in Array(data) do
new_event = LogStash::Event.new()
new_event.set('@timestamp', e['@timestamp'])
new_event.set('data', d)
new_event.set('namespace', e['namespace'])
new_event.set('resourceregion', e['resourceregion'])
new_event.set('resourceGroup', e['value'][0]['resourceGroup'])
new_event.set('valueUnit', e['value'][0]['unit'])
new_event.set('valueType', e['value'][0]['type'])
new_event.set('id', e['value'][0]['id'])
new_event.set('errorCode', e['value'][0]['errorCode'])
new_event.set('displayDescription', e['value'][0]['displayDescription'])
new_event.set('localizedValue', e['value'][0]['name']['localizedValue'])
new_event.set('valueName', e['value'][0]['name']['@value'])
new_event_block.call(new_event)
end
event.cancel()
"
}
if "_rubyexception" in [tags] {
drop {}
}
date {
match => [ "[data][timeStamp]", "yyyy-MM-dd'T'HH:mm:ssZZ" ]
}
mutate {
convert => {
"[data][count]" => "integer"
"[data][minimum]" => "integer"
"[data][total]" => "integer"
"[data][maximum]" => "integer"
"[data][average]" => "integer"
}
}
}
After processing, the obtained documents are saved to the Kafka topic using Logstash output:
output {
kafka {
bootstrap_servers => "localhost:9092"
client_id => "gk-eslapp01v"
topic_id => "azurelogs"
codec => json
}
}
Azure Application Insights metrics¶
Sample metrics:
- performanceCounters / exceptionsPerSecond
- performanceCounters / memoryAvailableBytes
- performanceCounters / processCpuPercentage
- performanceCounters / processIOBytesPerSecond
- performanceCounters / processPrivateBytes
Sample query:
GET https://api.applicationinsights.io/v1/apps/[appIdarówka/metrics/ nutsmetricId}
Metrics List:
- https://docs.microsoft.com/en-us/rest/api/application-insights/metrics/get
Energy Logserver GUI¶
Metrics¶
Metric data is recorded in the monthly indexes:
azure-metrics -% {YYYY.MM}
The pattern index in Energy Logserver GUI is:
azure-metrics *
Energy Logserver Discover data is available using the saved search: “[Azure Metrics] Metrics Details”
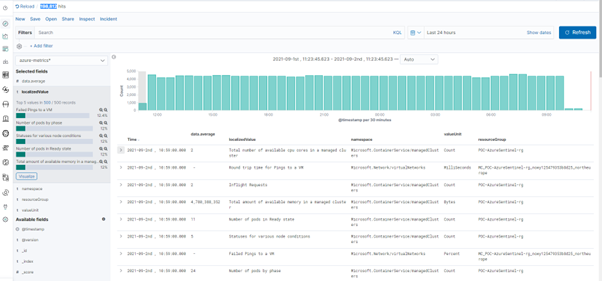
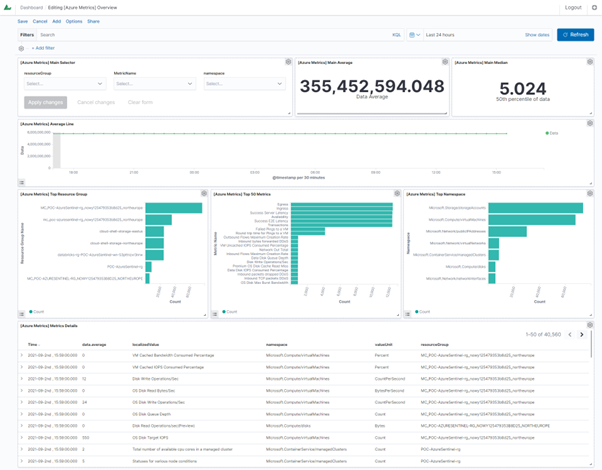
The analysis of the collected metrics is possible using the provided dashboard:
On which the following views have been placed:
- [Azure Metrics] Main Selector - a selector that allows you to search by name and select a resource group, metric or namespace for a filter.
- [Azure Metrics] Main Average - a numeric field that calculates the average value of a selected metric;
- [Azure Metrics] Main Median - numeric field that calculates the median of the selected metric;
- [Azure Metrics] Average Line - a line chart of the value of the selected metric over time;
- [Azure Metrics] Top Resource Group - horizontal bar chart of resource groups with the most metrics
- [Azure Metrics] Top Metrics - horizontal bar chart, metrics with the largest amount of data
- [Azure Metrics] Top Namespace - horizontal bar chart, namespace with the most metrics
- [Azure Metrics] Metrics Details - table containing details / raw data;
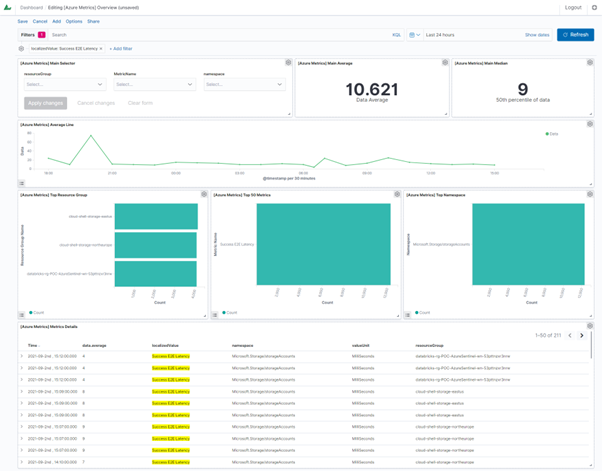
Dashboard with an active filter:
Events¶
Events are stored in the monthly indexes:
azure_events -% {YYYY.MM}
The index pattern in Energy Logserver GUI is:
azure_events *
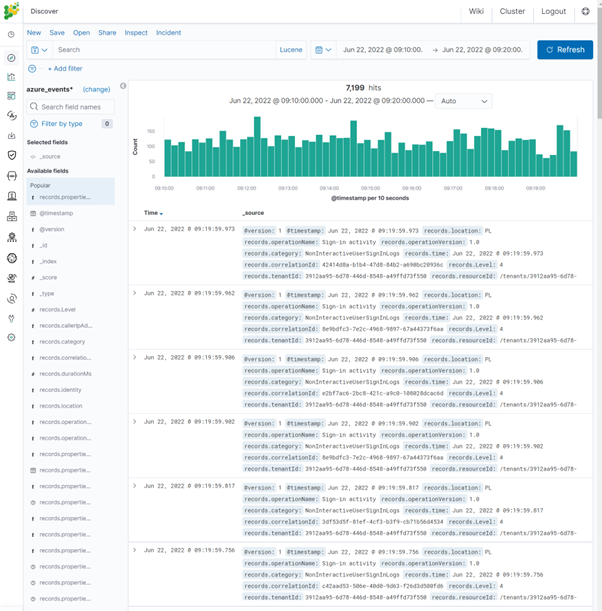
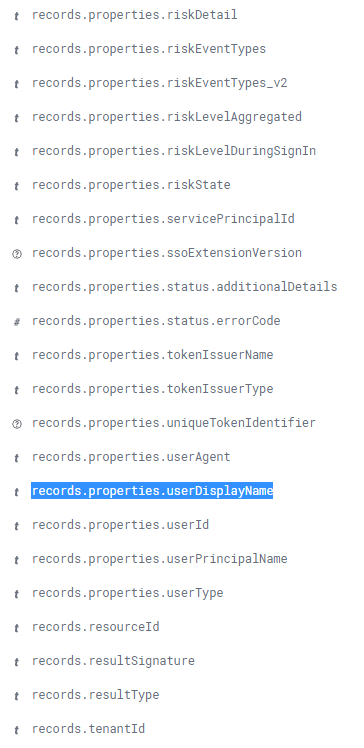
Examples of fields decoded in the event:
The analysis of the collected events is possible using the provided dashboard:
Componens:
- [AZURE] Event category - pie chart, division into event categories,
- [AZURE] Login Status - pie chart, login status breakdown,
- [AZURE] User localtion - map, location of logging in users,
- [AZURE] Client App Type - pie chart, division into client application type,
- [AZURE] Client APP - bar chart, the most used client application,
- [AZURE] Top activity type - pie chart, division into user activity type,
- [AZURE] Client Top App - table, the most frequently used client application,
- [AZURE] Failed login reason - save search, user access problems, raw data.
Google Cloud Platform¶
The Energy Logserver accepts data from the Google Cloud Platform using the Pub/Sub service. Pub/Sub is used for streaming analytics and data integration pipelines to ingest and distribute data. It’s equally effective as a messaging-oriented middleware for service integration or as a queue to parallelize tasks. https://cloud.google.com/pubsub/docs/overview
To fetch events from the GCP service add the following condition to the Logstash configuration file:
input {
google_pubsub {
# Your GCP project id (name)
project_id => "augmented-form-349311"
# The topic name below is currently hard-coded in the plugin. You
# must first create this topic by hand and ensure you are exporting
# logging to this pubsub topic.
topic => "topic_1"
# The subscription name is customizeable. The plugin will attempt to
# create the subscription (but use the hard-coded topic name above).
subscription => "sub_1"
# If you are running logstash within GCE, it will use
# Application Default Credentials and use GCE's metadata
# service to fetch tokens. However, if you are running logstash
# outside of GCE, you will need to specify the service account's
# JSON key file below.
json_key_file => "/etc/logstash/conf.d/tests/09_GCP/pkey.json"
# Should the plugin attempt to create the subscription on startup?
# This is not recommended for security reasons but may be useful in
# some cases.
#create_subscription => true
}
}
filter {}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "gcp-%{+YYYY.MM}"
user => "logstash"
password => "logstash"
ilm_enabled => false
}
}
Authentication to the Pub/Sub service must be done with a private key: https://cloud.google.com/iam/docs/creating-managing-service-account-keys#creating
F5¶
The Energy Logserver accepts data from the F5 system using the SYSLOG protocol. The F5 configuration procedure is as follows: https://support.f5.com/csp/article/K13080
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["F5"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘F5’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "F5" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
ssl => true
ssl_certificate_verification => false
index => "F5-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Aruba Devices¶
The Energy Logserver accepts data from the Aruba Devices system using the SYSLOG protocol. The Aruba Switches configuration procedure is as follows: https://community.arubanetworks.com/browse/articles/blogviewer?blogkey=80765a47-fe42-4d69-b500-277217f5312e
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["ArubaSW"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘ArubaSW’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "ArubaSW" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
ssl => true
ssl_certificate_verification => false
index => "ArubaSW-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Sophos Central¶
The Energy Logserver accepts data from the Sophos Central system using the API interface. The Sophos Central configuration procedure is as follows: https://github.com/sophos/Sophos-Central-SIEM-Integration
Pipeline configuration in Logstash collector:
input {
exec {
command => "/etc/lists/bin/Sophos-Central/siem.py -c /usr/local/Sophos-Central/config.ini -q"
interval => 60
codec => "json_lines"
}
}
filter {
date {
match => [ "[data][created_at]", "UNIX_MS" ]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "sophos-central-%{+YYYY.MM}"
user => "logstash"
password => "logstash"
}
}
Example of config.ini file:
/usr/local/Sophos-Central/config.ini
[login]
token_info = 'url: https://api4.central.sophos.com/gateway, x-api-key: dcaz, Authorization: Basic abdc'
client_id = UUID
client_secret = client-secrter
tenant_id =
auth_url = https://id.sophos.com/api/v2/oauth2/token
api_host = api.central.sophos.com
format = json
filename = stdout
endpoint = all
address = /var/run/syslog
facility = daemon
socktype = udp
state_file_path = siem_sophos.json
The Energy Logserver can make automatic configuration changes via the API in Sophos E-mail Appliance, such as: adding a domain to the blocked domain list. This is done by using the command alert method and entering the correct API request in the Path to script/command field.
FreeRadius¶
The Energy Logserver accepts data from the FreeRadius system using the SYSLOG protocol. The FreeRadius configuration procedure is as follows: https://wiki.freeradius.org/config/Logging
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["FreeRadius"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘FreeRadius’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "FreeRadius" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "FreeRadius-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Microsoft Advanced Threat Analytics¶
The Energy Logserver accepts data from the Advanced Threat Analytics system using the SYSLOG protocol with message in CEF format. The Advanced Threat Analytics configuration procedure is as follows: https://docs.microsoft.com/pl-pl/advanced-threat-analytics/cef-format-sa
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["ATA"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘ATA’
The event is recognized and decoded:
filter {
if [msg] =~ /CEF:/ {
grok {
keep_empty_captures => true
named_captures_only => true
remove_field => [
"msg",
"[cef][version]"
]
match => {
"msg" => [
"^%{DATA} CEF:%{NUMBER:[cef][version]}\|%{DATA:[cef][device][vendor]}\|%{DATA:[cef][device][product]}\|%{DATA:[cef] [device][version]}\|%{DATA:[cef][sig][id]}\|%{DATA:[cef][sig][name]}\|%{DATA:[cef][sig][severity]}\|%{GREEDYDATA:[cef] [extensions]}"
]
}
}
}
if "ATA" in [tags] {
if [cef][extensions] {
kv {
source => "[cef][extensions]"
remove_field => [
"[cef][extensions]",
"device_time"
]
field_split_pattern => "\s(?=\w+=[^\s])"
include_brackets => true
transform_key => "lowercase"
trim_value => "\s"
allow_duplicate_values => true
}
if [json] {
mutate {
gsub => [
"json", "null", '""',
"json", ":,", ':"",'
]
}
json {
skip_on_invalid_json => true
source => "json"
remove_field => [
"json"
]
}
}
mutate {
rename => { "device_ip" => "[device][ip]" }
rename => { "device_uid" => "[device][uid]" }
rename => { "internalhost" => "[internal][host]" }
rename => { "external_ip" => "[external][ip]" }
rename => { "internalip" => "[internal][ip]" }
}
}
}
}
}
Using the assigned tag, the documents is send to the appropriate index:
output {
if "ATA" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "ATA-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
CheckPoint Firewalls¶
The Energy Logserver accepts data from the CheckPoint Firewalls system using the SYSLOG protocol. The CheckPoint Firewalls configuration procedure is as follows: https://sc1.checkpoint.com/documents/SMB_R80.20/AdminGuides/Locally_Managed/EN/Content/Topics/Configuring-External-Log-Servers.htm?TocPath=Appliance%20Configuration%7CLogs%20and%20Monitoring%7C_____3
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["CheckPoint"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘CheckPoint’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "F5BIGIP" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "CheckPoint-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
The Energy Logserver can make automatic configuration changes via the API in Checkpoint firewalls such as adding a rule in the firewall. This is done using the command alert method and entering the correct API request in the Path to script/command field.
WAF F5 Networks Big-IP¶
The Energy Logserver accepts data from the F5 system using the SYSLOG protocol. The F5 configuration procedure is as follows: https://support.f5.com/csp/article/K13080
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["F5BIGIP"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘F5’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "F5BIGIP" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
ssl => true
ssl_certificate_verification => false
index => "F5BIGIP-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Infoblox DNS Firewall¶
The Energy Logserver accepts data from the Infoblox system using the SYSLOG protocol. The Infoblox configuration procedure is as follows: https://docs.infoblox.com/space/NAG8/22252249/Using+a+Syslog+Server#Specifying-Syslog-Servers
To identify and collect events from a Infoblox, is nessery to use Filebeat with infoblox module.
To run Filebeat with infoblox moduel run following commnds:
filebeat modules enable infoblox
Configure output section in /etc/filebat/filebeat.yml file:
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver can make automatic configuration changes via an API in the Infoblox DNS Firewall, e.g.: automatic domain locking. This is done using the command alert method and entering the correct API request in the Path to script/command field.
CISCO Devices¶
The Energy Logserver accepts data from the Cisco devices - router, switch, firewall and access point using the SYSLOG protocol. The Cisco devices configuration procedure is as follows: https://www.ciscopress.com/articles/article.asp?p=426638&seqNum=3
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["CISCO"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘CISCO’. Using the assigned tag, the documents is send to the appropriate index:
output {
if "CISCO" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "CISCO-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Microsoft Windows Systems¶
The Energy Logserver getting events from Microsoft Systems using the Winlogbeat agent.
To identify and collect events from a Windows eventchannel, it is nessery to setup following parameters in winlobeat.yml configuration file.
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
output.logstash:
# The Logstash hosts
hosts: ["$IP:5044"]
Where $IP is IP address of Energy Logserver datanode.
Linux Systems¶
The Energy Logserver accepts data from the Linux systems using the SYSLOG protocol.
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["LINUX"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘LINUX’. Using the assigned tag, the documents is send to the appropriate index:
output {
if "LINUX" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "LINUX-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
AIX Systems¶
The Energy Logserver accepts data from the AIX systems using the SYSLOG protocol.
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["AIX"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘AIX’. Using the assigned tag, the documents is send to the appropriate index:
output {
if "AIX" in [tags] {
elasticsearch {
hosts => "http://localhost:9200"
index => "AIX-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
Microsoft Windows DNS, DHCP Service¶
The Energy Logserver accepts data from the Microsoft DNS and DHCP services using the Filebeat agent.
To identify and collect events from Microsoft DNS and DHCP services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- c:\\Path_to_DNS_logs\*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Microsoft IIS Service¶
The Energy Logserver accepts data from the Microsoft IIS services using the Filebeat agent.
To identify and collect events from Microsoft IIS services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- c:\\Path_to_IIS_logs\*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Apache Service¶
The Energy Logserver accepts data from the Linux Apache services using the Filebeat agent.
To identify and collect events from Linux Apache services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in /etc/filebat/filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- /var/log/apache/*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Microsoft Exchange¶
The Energy Logserver accepts data from the Microsoft Exchange services using the Filebeat agent.
To identify and collect events from Microsoft Exchange services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- c:\\Path_to_Exchange_logs\*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Microsoft Exchange message tracking¶
The message tracking log is a detailed record of all activity as mail flows through the transport pipeline on Mailbox servers and Edge Transport servers. You can use message tracking for message forensics, mail flow analysis, reporting, and troubleshooting.
By default, Exchange uses circular logging to limit the message tracking log based on file size and file age to help control the hard disk space that’s used by the log files. To configure the message tracking log, see the documentation: https://docs.microsoft.com/en-us/exchange/mail-flow/transport-logs/configure-message-tracking?view=exchserver-2019
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- "%ExchangeInstallPath%TransportRoles\Logs\MessageTracking\*"
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Microsoft AD, Radius, Network Policy Server¶
The Energy Logserver accepts data from the Active Directory, Radius, Network Policy Server services using the Winlogbeat agent.
To identify and collect events from Active Directory, Radius, Network Policy Server services, is nessery to set correct path do logs in Winlogbeat configuration file.
Configure output section in C:\Program Files (x86)\winlogbeat\winlogbeat.yml file:
winlogbeat.event_logs:
- name: Application
- name: System
- name: Security
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
winlogbeat test config
and:
winlogbeat test output
The Energy Logserver save collected data in winlogbeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Microsoft MS SQL Server¶
The Energy Logserver accepts data from the Microsoft MS SQL Server services using the Filebeat agent.
To identify and collect events from Microsoft MS SQL Server services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- "C:\Program Files\Microsoft SQL Server\MSSQL10_50.SQL\MSSQL\Log\*LOG*"
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
MySQL Server¶
The Energy Logserver accepts data from the MySQL Server services using the Filebeat agent.
To identify and collect events from MySQL Server services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in /etc/filebeat/filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- /var/log/mysql/*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Oracle Database Server¶
The Energy Logserver accepts data from the Oracle Database Server services using the Filebeat agent.
To identify and collect events from Oracle Database Server services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in /etc/filebeat/filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- /var/log/oracle/*.xml
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Postgres Database Server¶
The Energy Logserver accepts data from the Postgres Database Server services using the Filebeat agent.
To identify and collect events from Oracle Postgres Server services, is nessery to set correct path do logs in Filebeat configuration file.
Configure output section in /etc/filebeat/filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- //opt/postgresql/9.3/data/pg_log/*.log
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
VMware Platform¶
The Energy Logserver accepts data from the VMware platform using the SYSLOG protocol. The VMware vCenter Server configuration procedure is as follows: https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere.monitoring.doc/GUID-FD51CE83-8B2A-4EBA-A16C-75DB2E384E95.html
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if "syslog" in [tags] {
if [host] == "$IP" {
mutate {
add_tag => ["vmware"]
}
}
}
}
Where $IP is IP address of source system and each document coming from the address will be tagged with ‘VMware vCenter Server’ Using the assigned tag, the documents is send to the appropriate index:
output {
if "vmware" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
ssl => true
ssl_certificate_verification => false
index => "vmware-%{+YYYY.MM.dd}"
user => "logstash"
password => "logstash"
}
}
}
VMware Connector¶
The Energy Logserver accepts logs from the VMware system using the VMware logstash pipeline.
We need set configuration in script following location:
/logstash/lists/bin/vmware.sh
And set the connection parameters:
export GOVC_URL="https://ESX_IP_ADDRESS"
export GOVC_USERNAME="ESX_login"
export GOVC_PASSWORD="ESX_password"
export GOVC_INSECURE="true"
The documents is send to the appropriate index:
output {
if "vmware" in [tags] {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "vmware-%{+YYYY.MM}"
user => "logstash"
password => "logstash"
ilm_enabled => false
}
}
}
Network Flows¶
The Energy Logserver has the ability to receive and process various types of network flows. For this purpose, the following input ports have been prepared:
- IPFIX, Netflow v10 - 4739/TCP, 4739/UDP
- NetFlow v5,9 - 2055/UDP
- sFlow - 6343/UDP
Example of inputs configuration:
input {
udp {
port => 4739
codec => netflow {
ipfix_definitions => "/etc/logstash/netflow/definitions/ipfix.yaml"
versions => [10]
target => ipfix
include_flowset_id => "true"
}
type => ipfix
tags => ["ipfix", "v10", "udp"]
}
tcp {
port => 4739
codec => netflow {
ipfix_definitions => "/etc/logstash/netflow/definitions/ipfix.yaml"
versions => [10]
target => ipfix
include_flowset_id => "true"
}
type => ipfix
tags => ["ipfix", "v10", "tcp"]
}
}
input {
udp {
port => 2055
type => netflow
codec => netflow {
netflow_definitions => "/etc/logstash/netflow/definitions/netflow.yaml"
versions => [5,9]
}
tags => ["netflow"]
}
}
input {
udp {
port => 6343
type => sflow
codec => sflow
tags => ["sflow"]
}
}
Citrix XenApp and XenDesktop¶
This Energy Logserver has the ability to acquire data from Citrix XenApp and XenDesktop.
An example command to enable Citrix Broker Service log to a file is as follows:
BrokerService.exe –Logfile "C:\XDLogs\Citrix Broker Service.log"
Or there is the possibility of extracting results, data from a report generated using the console:
The Energy Logserver accepts data from Citrix XenApp and XenDesktop server using the Filebeat agent.
To identify and collect events from Citrix XenApp and XenDesktop servers, you need to set the correct path to the logs in the Filebeat configuration file.
Configure output section in C:\Program Files (x86)\filebeat\filebeat.yml file:
filebeat.inputs:
- type: log
paths:
- "C:\XDLogs\Citrix Broker Service.log"
output.logstash:
hosts: ["127.0.0.1:5044"]
Test the configuration:
filebeat test config
and:
filebeat test output
The Energy Logserver save collected data in filebeat-* index pattern and its available to review in the Discover module.
If additional agent data information is required, e.g.: IP address, add the following section in the agent configuration file:
processors:
- add_host_metadata:
netinfo.enabled: true
Sumologic Cloud SOAR¶
The Energy Logserver has the ability to forward detected alerts to Sumologic Cloud SOAR. To do this, select the “syslog” method in the alert definition and set the following parameters:
- Host
- Port
- Protocol
- Logging Level
- Facility
Energy Logserver has the ability to create security dashboards from data found in SOAR, such as statistics. It has the ability to create and configure master views from extracted SOAR data.
An example of an API request retrieving data:
curl -X GET "https://10.4.3.202/incmansuite_ng/api/v2/kpi?output_set=Weekly%20summary&type=json" -H "accept: application/json" -H "Authorization: bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzUxMiJ9. eyJpYXQiOjE2NTc3MTg2ODAsImp0aSI6IjdmMzg1ZDdhLTc1YjYtNGZmMC05YTdmLTVkMmNjYTjZjTQ0YiIsImlzcyI6IkluY01hbiA1LjMuMC4wIiwibmJmIjoxNjU3NzE4NjgwLCJleHAiOm51bGwsImRhdGEiOnsidXNlcklkIjoxfX0. pCJlM9hxj8VdavGuNfIuq1y5Dwd9kJT_UMyoRca_gUZjUXQ85nwEQZz_QEquE1rXTgVW9TO__gDNjY30r8yjoA" -k
Example of request response:
[{"[INCIDENT] Created by": "System","[INCIDENT] Owner": "IncMan Administrator","[INCIDENT] Kind": "Forensic - Incident response","[INCIDENT] Status": "Open","[INCIDENT] Incident ID": "2022","[INCIDENT] Opening time": "07/15/22 10:47:11","[INCIDENT] Closing time":"","[INCIDENT] Category": "General","[INCIDENT] Type": "General, Incident Response","[OBSERVABLES] EMAIL":["adam@it.emca.pl"]},{"[INCIDENT] Created by": "System","[INCIDENT] Owner": "IncMan Administrator","[INCIDENT] Kind": "Forensic - Incident response","[INCIDENT] Status": "Open","[INCIDENT] Incident ID": "ENE-LOGS EVENTS FROM LOGSERVER 2022-07-15 08:23:00","[INCIDENT] Opening time": "07/15/22 10:23:01","[INCIDENT] Closing time":"","[INCIDENT] Category": "General","[INCIDENT] Type": "General, Intrusion attempt"},[{"[INCIDENT] Created by": "System","[INCIDENT] Owner": "IncMan Administrator","[INCIDENT] Kind": "Forensic - Incident response","[INCIDENT] Status": "Open","[INCIDENT] Incident ID": "ENE-LOGS EVENTS FROM LOGSERVER 2022-07-15 08:20: 49","[INCIDENT] Opening time": "07/15/22 10:20:50","[INCIDENT] Closing time":"","[INCIDENT] Category": "General","[INCIDENT] Type": "General, Intrusion attempt"}]]
Integration pipeline configuration:
input {
exec {
command => ""https://10.4.3.202/incmansuite_ng/api/v2/kpi?output_set=Weekly%20summary&type=json" -H "accept: application/json" -H "Authorization: bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzUxMiJ9. eyJpYXQiOjE2NTc3MTg2ODAsImp0aSI6IjdmMzg1ZDdhLTc1YjYtNGZmMC05YTdmLTVkMmNjYTjZjTQ0YiIsImlzcyI6IkluY01hbiA1LjMuMC4wIiwibmJmIjoxNjU3NzE4NjgwLCJleHAiOm51bGwsImRhdGEiOnsidXNlcklkIjoxfX0. pCJlM9hxj8VdavGuNfIuq1y5Dwd9kJT_UMyoRca_gUZjUXQ85nwEQZz_QEquE1rXTgVW9TO__gDNjY30r8yjoA" -k"
interval => 86400
}
}
# optional
filter {}
output {
elasticsearch {
hosts => [ "http://localhost:9200" ]
index => "soar-%{+YYYY.MM}"
user => "logserver"
password => "logserver"
}
}
Microsfort System Center Operations Manager¶
The Energy Logserver has the ability to integrate with MS SCOM (System Center Operations Manager) monitoring systems to monitor metrics and service availability in the context of the end system user.
An example of the integration pipeline configuration with SCOM:
input {
# scom
jdbc {
jdbc_driver_library => "/usr/share/logstash/jdbc/mssql-jdbc-6.2.2.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://VB2010000302;databaseName=OperationsManagerDW2012;"
jdbc_user => "PerfdataSCOM"
jdbc_password => "${SCOM_PASSWORD}"
jdbc_default_timezone => "UTC"
statement_filepath => "/usr/share/logstash/plugin/query"
schedule => "*/5 * * * *"
sql_log_level => "warn"
record_last_run => "false"
clean_run => "true"
tags => "scom"
}
}
# optional filter section
filter {}
output {
if "scom" in [tags] {
elasticsearch {
hosts => [ "http://localhost:9200" ]
index => "scom-%{+YYYY.MM}"
user => "logstash"
password => "logstash"
}
}
}
The SLQ query stored in /usr/share/logstash/plugin/query file:
#query
SELECT
Path,
FullName,
ObjectName,
CounterName,
InstanceName,
SampleValue AS Value,
DateTime
FROM Perf.vPerfRaw pvpr WITH (NOLOCK)
INNER JOIN vManagedEntity vme WITH (NOLOCK)
ON pvpr.ManagedEntityRowId = vme.ManagedEntityRowId
INNER JOIN vPerformanceRuleInstance vpri WITH (NOLOCK)
ON pvpr.PerformanceRuleInstanceRowId = vpri.PerformanceRuleInstanceRowId
INNER JOIN vPerformanceRule vpr WITH (NOLOCK)
ON vpr.RuleRowId = vpri.RuleRowId
WHERE ObjectName IN (
'AD FS',
'AD Replication',
'Cluster Disk',
'Cluster Shared Volume',
'DirectoryServices',
'General Response',
'Health Service',
'LogicalDisk',
'Memory',
'Network Adapter',
'Network Interface',
'Paging File',
'Processor',
'Processor Information',
'Security System-Wide Statistics',
'SQL Database',
'System',
'Web Service'
)
AND CounterName IN (
'Artifact resolution Requests',
'Artifact resolution Requests/sec',
'Federation Metadata Requests',
'Federation Metadata Requests/sec',
'Token Requests',
'Token Requests/sec',
'AD Replication Queue',
'Replication Latency',
'Free space / MB',
'Free space / Percent',
'Total size / MB',
'ATQ Outstanding Queued Requests',
'ATQ Request Latency',
'ATQ Threads LDAP',
'ATQ Threads Total',
'Active Directory Last Bind',
'Global Catalog Search Time',
'agent processor utilization',
'% Free Space',
'Avg. Disk Queue Length',
'Avg. Disk sec/Read',
'Avg. Disk sec/Write',
'Current Disk Queue Length',
'Disk Bytes/sec',
'Disk Read Bytes/sec',
'Disk Reads/sec',
'Disk Write Bytes/sec',
'Disk Writes/sec',
'Free Megabytes',
'Bytes Total/sec',
'Bytes Received/sec',
'Bytes Sent/sec',
'Bytes Total/sec',
'Current Bandwidth',
'% Processor Time',
'% Usage',
'% Committed Bytes In Use',
'Available Bytes',
'Available MBytes',
'Cache Bytes',
'Cache Faults/sec',
'Committed Bytes',
'Free System Page Table Entries',
'Page Reads/sec',
'Page Writes/sec',
'Pages/sec',
'PercentMemoryUsed',
'Pool Nonpaged Bytes',
'Pool Paged Bytes',
'KDC AS Requests',
'KDC TGS Requests',
'Kerberos Authentications',
'NTLM Authentications',
'DB Active Connections',
'DB Active Sessions',
'DB Active Transactions',
'DB Allocated Free Space (MB)',
'DB Allocated Size (MB)',
'DB Allocated Space (MB)',
'DB Allocated Space Used (MB)',
'DB Available Space Total (%)',
'DB Available Space Total (MB)',
'DB Avg. Disk ms/Read',
'DB Avg. Disk ms/Write',
'DB Disk Free Space (MB)',
'DB Disk Read Latency (ms)',
'DB Disk Write Latency (ms)',
'DB Total Free Space (%)',
'DB Total Free Space (MB)',
'DB Transaction Log Available Space Total (%)',
'DB Transactions/sec',
'DB Used Space (MB)',
'Log Free Space (%)',
'Log Free Space (MB)',
'Log Size (MB)',
'Processor Queue Length',
'System Up Time',
'Connection Attempts/sec',
'Current Connections'
)
AND DateTime >= DATEADD(MI, -6, GETUTCDATE())
JBoss¶
The Energy Logserver accepts data from the JBoss platform using the Filebeat agent. Example configuration file for Filebeat:
filebeat:
prospectors:
-
paths:
- /var/log/messages
- /var/log/secure
input_type: log
document_type: syslog
-
paths:
- /opt/jboss/server/default/log/server.log
input_type: log
document_type: jboss_server_log
multiline:
pattern: "^[[:digit:]]{4}-[[:digit:]]{2}-[[:digit:]]{2}"
negate: true
match: after
max_lines: 5
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["10.1.1.10:5044"]
bulk_max_size: 1024
tls:
certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
shipper:
logging:
to_syslog: false
to_files: true
files:
path: /var/log/mybeat
name: mybeat
rotateeverybytes: 10485760 # = 10MB
keepfiles: 2
level: info
To identify events from a specific source, add the following condition to the Logstash configuration file:
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{SYSLOGHOST:hostname} %{DATA:program}(?:\[%{POSINT:pid}\])?: %{GREEDYDATA:msgdetail}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
else if [type] == "jboss_server_log" {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} +\[%{DATA:logger}\] %{GREEDYDATA:msgdetail}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
}
}
Energy Security Feeds¶
Energy Security Feeds boosts Your security detection rules. Get connected to fresh lists of Indicators of Compromise (IoCs) that contain crucial data about malware activities, attacks, financial fraud or any suspicious behaviour detected using our public traps. Energy Security Feeds is a set of rich dictionary files ready to be integrated in SIEM Plan. Indicators like ip adresses, certhash, domain, email, filehash, filename, regkey, url are daily updated from our lab which is integrated with MISP ecosystem. The default feeds are described in a simple JSON format.
Configuration¶
Bad IP list update¶
To update bad reputation lists and to create .blacklists index, you have to run following scripts:
/etc/logstash/lists/bin/misp_threat_lists.sh
Scheduling bad IP lists update¶
This can be done in cron (host with Logstash installed):
0 6 * * * logstash /etc/logstash/lists/bin/misp_threat_lists.sh
or with Kibana Scheduller app (only if Logstash is running on the same host).
- Prepare script path:
/bin/ln -sfn /etc/logstash/lists/bin /opt/ai/bin/lists
chown logstash:kibana /etc/logstash/lists/
chmod g+w /etc/logstash/lists/
- Log in to Energy Logserver GUI and go to Scheduler app. Set it up with below options and push “Submit” button:
Name: MispThreatList Cron pattern: 0 1 * * * Command: lists/misp_threat_lists.sh Category: logstash After a couple of minutes check for blacklists index:
curl -sS -u user:password -XGET '127.0.0.1:9200/_cat/indices/.blacklists?s=index&v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .blacklists Mld2Qe2bSRuk2VyKm-KoGg 1 0 76549 0 4.7mb 4.7mb